AI/ML Engineer specializing in Computer Vision & Generative AI
Solving complex engineering problems through ML, computer vision, and generative AI — NYU & IIT Madras alum | Intel award-winning intern | Research Assistant at NYU
AI/ML Engineer specializing in Computer Vision & Generative AI
Solving complex engineering problems through ML, computer vision, and generative AI — NYU & IIT Madras alum | Intel award-winning intern | Research Assistant at NYU
👋 Hello! I'm Manoj, an AI/ML engineer who thrives on solving complex challenges at the intersection of computer vision, generative AI, and 3D rendering. My passion isn't just research — it's turning cutting-edge ideas into practical, impactful solutions.
I’m a recent Master’s in Computer Engineering graduate from New York University and an alumnus of IIT Madras. Currently, I’m a research assistant at the NYU Video Lab (advised by Prof. Yao Wang), developing diffusion-based solutions for 3D scene refinement and reconstruction.
I love bringing applied AI projects to life. During my internship at Intel, I received an Excellency Award for developing novel vision-based automation tools for integrated chip design validation. I’ve also contributed to fast-growing startups like Preimage and GalaxEye Space, where I worked on 3D reconstruction pipelines and satellite image super-resolution, respectively.
On the academic side, I worked on "U2NeRF: Unsupervised Underwater Image Restoration and Neural Radiance Fields" as part of my master’s thesis, focusing on 3D-consistent unsupervised image restoration for underwater scenes. This work was later published at the ICLR ’24 Tiny Papers conference, held in Vienna.
🚀 I’m always excited to connect with teams pushing the boundaries of AI for engineering, robotics, and visual intelligence. If that sounds like your world, I’d love to connect and explore opportunities to build something impactful together.
A timeline of my professional roles and contributions.
Aug 2025 – Present (New York City, NY)
Jun 2024 – Aug 2024 (Santa Clara, CA)
Aug 2022 – May 2023 (Chennai, India)
Sep 2022 – Dec 2022 (Bangalore, India)
May 2022 – Jul 2022 (Remote)
Dec 2021 – Jan 2022 (Chennai, India)
Sep 2023 – May 2025 (New York, NY)
Aug 2018 – Jul 2023 (Chennai, India)
Here are some of the projects I'm proud of. Feel free to check them out.


Self-supervised transformer-based framework achieving joint underwater image restoration and 3D reconstruction, embedding physics-informed light modeling for realistic view synthesis.

Diffusion-guided framework integrating 2D video priors with 3D Gaussian Splatting to improve sparse-view reconstruction, enhancing 3D view consistency through pose-conditioned feature alignment.
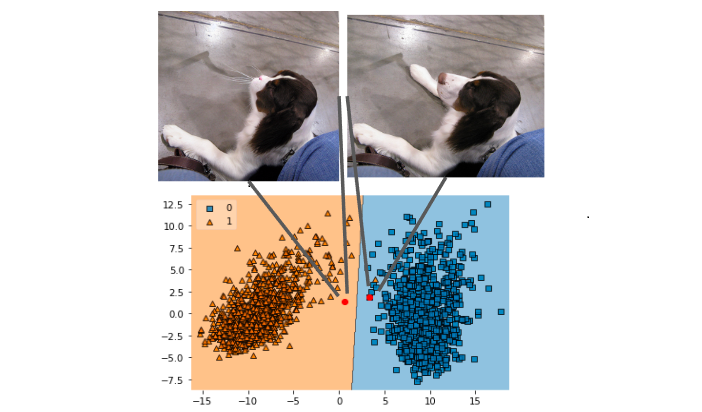
Text-guided counterfactual generation framework combining CLIP and Stable Diffusion to inpaint high-confidence regions, achieving fine-grained attribute manipulation while preserving over 90% of original content.

GAN-based system that fuses SAR and optical images to turn low-resolution satellite data into sharper, more detailed outputs using cross-domain feature alignment.

Implicit ML-framework that reconstructs 3D geometry from point clouds, learning a continuous function (occupancy or SDF) over space.


Deep-learning model that detects and segments defects on steel surfaces from images, generating pixel-wise masks for precise localization and handling various defect types.
Key accomplishments and recognitions received throughout my career.
Intel Corporation
Awarded the "Impact Award" during my Graduate Engineering Internship for delivering high-quality work ahead of schedule and demonstrating exceptional productivity.
ICLR Conference, Vienna
Research paper titled "U2NeRF: Unsupervised Underwater Image Restoration and Neural Radiance Fields" accepted and published at the prestigious International Conference on Learning Representations (ICLR), Tiny Papers track.
IIT Kanpur, India
Awarded Bronze (3rd place) in the Chandrayaan Moon Mapping Challenge organized by ISRO, representing the IIT Madras contingent at the 2023 Inter-IIT Tech Meet.
IIT Kanpur, India
Secured an All India Rank of 1467 in the highly competitive JEE Advanced, placing among the top 0.1% engineering aspirants in India.
NCERT, India
Awarded the prestigious NTSE Scholarship, granted to Grade 10 students ranking in the top 0.4% nationwide.
I'm currently open to new opportunities and collaborations.. If you have a project in mind or just want to say hi, feel free to reach out!
Say Hello